So I bought one of the new NVIDIA cards (RTX Pro Blackwell Workstation Edition) and have been playing around.
This card is just so mean! Chews through just about anything in batch while staying interactive and scrubbable.
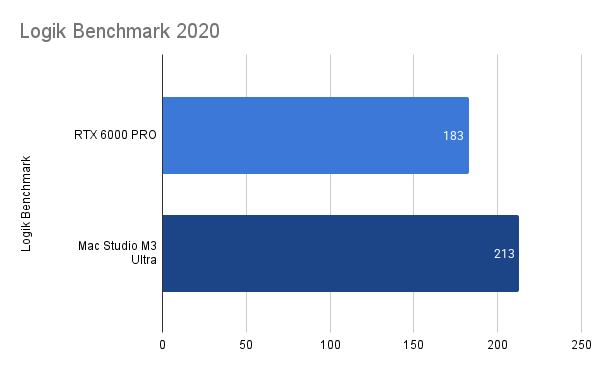
Initial benchmarks include the Logik bench and also further direct comparison against a current top-flight Mac Studio (M3 Ultra, 32/80 core 256GB RAM). Logik benchmark here:
It would seem that both machines exceed any previously posted benchmarks (although if I’m reading the results correctly, somehow there’s not a single Logik benchmark posting with a 6000 Ada? If someone could run that test it might provide a starting point comparison between pro generations).
Ultimately though, the Logik benchmark test doesn’t relate very closely to my workflow- which is heavy shot work with hi-res 16bit fp. Logik results aside, it’s just immediately obvious that my Linux box with the new card is WAY faster than the Mac Studio in batch.
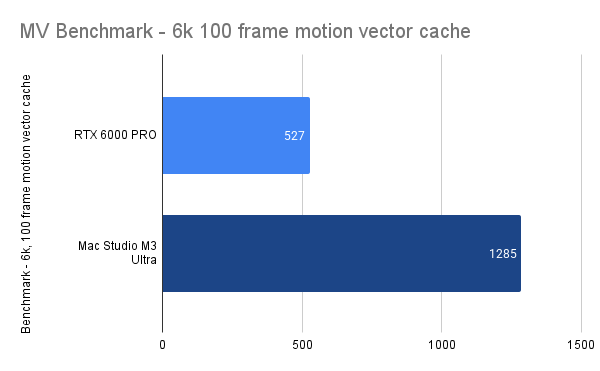
For my “real-world” benchmarks I’m currently relying on actual job schematics that I’m unable to share, but I could probably come up with a generic version eventually. The general finding is, the heavier the comp, the more the 6000 Pro separates from the Mac. See below:
Would be interesting to get more direct comparisons between the new card and prev-gen NVIDIA cards- I’ve been using a 4090 so I can’t make any pro comparisons directly. (BTW, the 4090 is actually also faster than this Mac Studio, but hits a brick wall when VRAM fills up so it’s inherently limited as a workstation card. I will be testing 4090s and maybe 5090s for burn in the near future. )
Caveats & issues: Drivers/compatibility are still bleeding edge… BorisFX ML tools currently crash due to some kind of CUDA library mismatch (case submitted). Flame runs smoothly on the currently NVIDIA certified driver version (570.169) but seems to only utilize 1/2 of the VRAM (case submitted). Meanwhile I did get faster performance and seemingly unlimited VRAM usage from a New Feature Branch version, but this version also broke motion vectors entirely so I’ve bailed on that).
Although not technically as deep as your benchmarks I have a P620 with ADA6000 and MacStudio M2 Ultra with 192 GB RAM. Logik benchmark is around 4:05 on P620 and 9:00 on the M2 Ultra.
@Sinan - did you ever consider adding a particle animation setup for the benchmarking? perhaps a 1200 frame explosion, or a 1200 frame emission, or spawning lots of the prepackaged geometries?
Thanks @sinan that helps … so on the Logik benchmark we see roughly a 25% drop in render times going from Ada to Blackwell. On the Mac side generally, it’s interesting how much variance there has been between some people testing in the 4-5 minute range and others in the 8-9 range. My M3 result of 3:33 does make me wonder if I’m in a group that’s somehow seeing inflated numbers, but I’m taking care to follow the directions (flush all renders, focus on top track, and hit just “Render”, not “Render Selected”. That being said, it doesn’t surprise me that the new Mac Studio benches as an extremely capable machine for timeline-oriented workflows particularly.
As for batch, as @philm said a particle rig benchmark could be great- I’ve been thinking about a prototype benchmark that could just be a series of compasses designed to test a few different tasks, each one able to be rendered individually or also all tied together. I’m a bit tied up with a project currently but could try to throw a rough idea out there soon for thoughts…
That’s right, all the numbers in the bar charts represent seconds to render… and that number in the section quoted there (570.169) is just the NVIDIA driver version that seems to work the best so far. (For anyone wanting to tinker with drivers, be sure to always use the “–install-libglvnd” flag while running NVIDIA installers).
No doubt it’s crazy expensive! (some places selling for $10.5k USD but I got mine on Newegg for $9k USD + tax). Still, I feel like this belongs in a totally different category than my M3 Ultra Mac Studio in terms of what it allows me to do. If a client throws out a bunch of tweaks and wants to see it right now, I can bypass any precomps and everything stays workable. I can move through the schematic, set a viewing context pretty far downstream of my work and still get good responsiveness.
I do think the previous generation cards, especially now that they are down to about 5k on eBay, are still a better value proposition right now for many situations. This is why I’m thinking it would be great to have more extensive direct comparison between these cards, so everybody can decide for themselves if that shiny $10k Blackwell card is really worth it