Starting a new thread to share some learnings from the trenches of ComfyUI
Many of us have watched Doug Hogan’s course, and it has set a nice baseline on how to approach our workflows with ComfyUI. But it doesn’t have as clear roadmap of how you go beyond the course (and maybe combining a few lessons into a new workflow, like the clean plate workflow I came up with), but explore further directions.
Turns out RunComfy has a whole section of sample workflows: ComfyUI Workflows | Runnable Guaranteed with Pre-set Nodes & Models . Everything from Fashion Fitting (switching out garments), keeping a character consistent across multiple videos, lipsync, character turn-around, relighting, trajectory motion control, and more.
It takes one button to run these workflows on RunComfy, fully loaded. Or you can just them onto a medium machine, download the workflow .json and then put that on your local install and evolve it without the clock ticking on you. Of course you need to chase down various nodes and models. But that’s always the case. Their Discord also puts a message into their Announcement channel every time the add a new workflow.
One thing I discovered while playing with one of these locally after downloading it from RunComfy - the ability to use your LLMs inside your RunComfy workflow. That workflow came with an OpenAI node. But there are also Claude nodes available. You will need to get an API Key and link it to your existing ChatGPT/Claude account and it will incur some charges (but much less than paying for a whole machine).
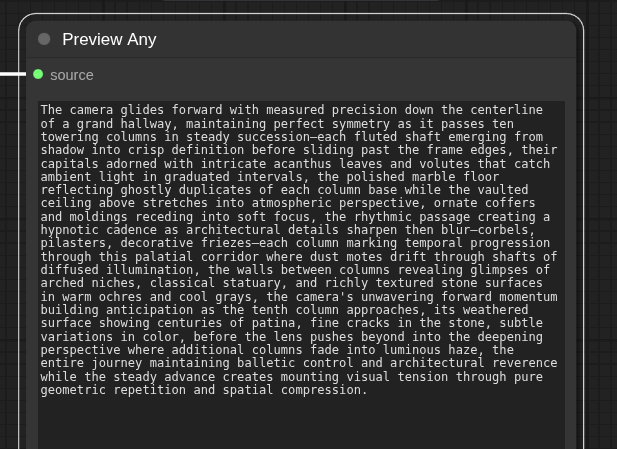
Claude (which I’m using) has a ‘describe image’ and ‘combine text’ node. So you don’t have to manually run your LLM to create prompts, but you can do that right as part of your node tree. Pipe the image into a describe node, then tweak the overall prompt, combine the two and you’re off to the races.